
Comment améliorer la pertinence des chatbots d’IA générative : Fine-tuning versus RAG
Chatbot d’IA générative : le défi de la pertinence des réponses
Les Grands Modèles de Langage (LLM) ont révolutionné le domaine de l'Intelligence Artificielle en permettant aux machines de générer du texte de qualité humaine. Cependant, ces modèles ne sont pas sans limites. Aujourd’hui, les chatbots basés sur l’IA générative peuvent produire des réponses incohérentes, peu pertinentes voire erronées, en particulier lorsqu'ils sont confrontés à des requêtes complexes ou à des contextes ambigus. De plus, les chatbots d'IA générative peuvent souffrir des "hallucinations", phénomène qui les poussent à communiquer des informations qui ne sont pas pertinentes ou même réelles. Ce manque de fiabilité peut entraîner une expérience utilisateur insatisfaisante et une perte de confiance dans cette technologie.
C'est dans ce contexte que le fine-tuning et la RAG (Retrieval Augmented Generation, ou Génération Augmentée de Récupération), ont émergé comme des solutions prometteuses pour relever ces défis en personnalisant et en affinant les interactions entre les utilisateurs et l'IA. Si l’objectif de ces deux méthodes consiste à améliorer la pertinence et la qualité des réponses fournies par les chatbots, elles reposent sur des stratégies bien distinctes aux résultats inégaux.
Fine-tuning : une méthode pour optimiser les résultats d’une IA générative
Comprendre le fine-tuning
Pour que les chatbots d’Intelligence Artificielle générative soient réellement efficaces, il est essentiel qu’ils soient entrainés ou aient connaissance des données spécifiques à leur domaine d'application. La méthode du fine-tuning est l’une des approches courantes utilisées pour améliorer les performances des LLM.
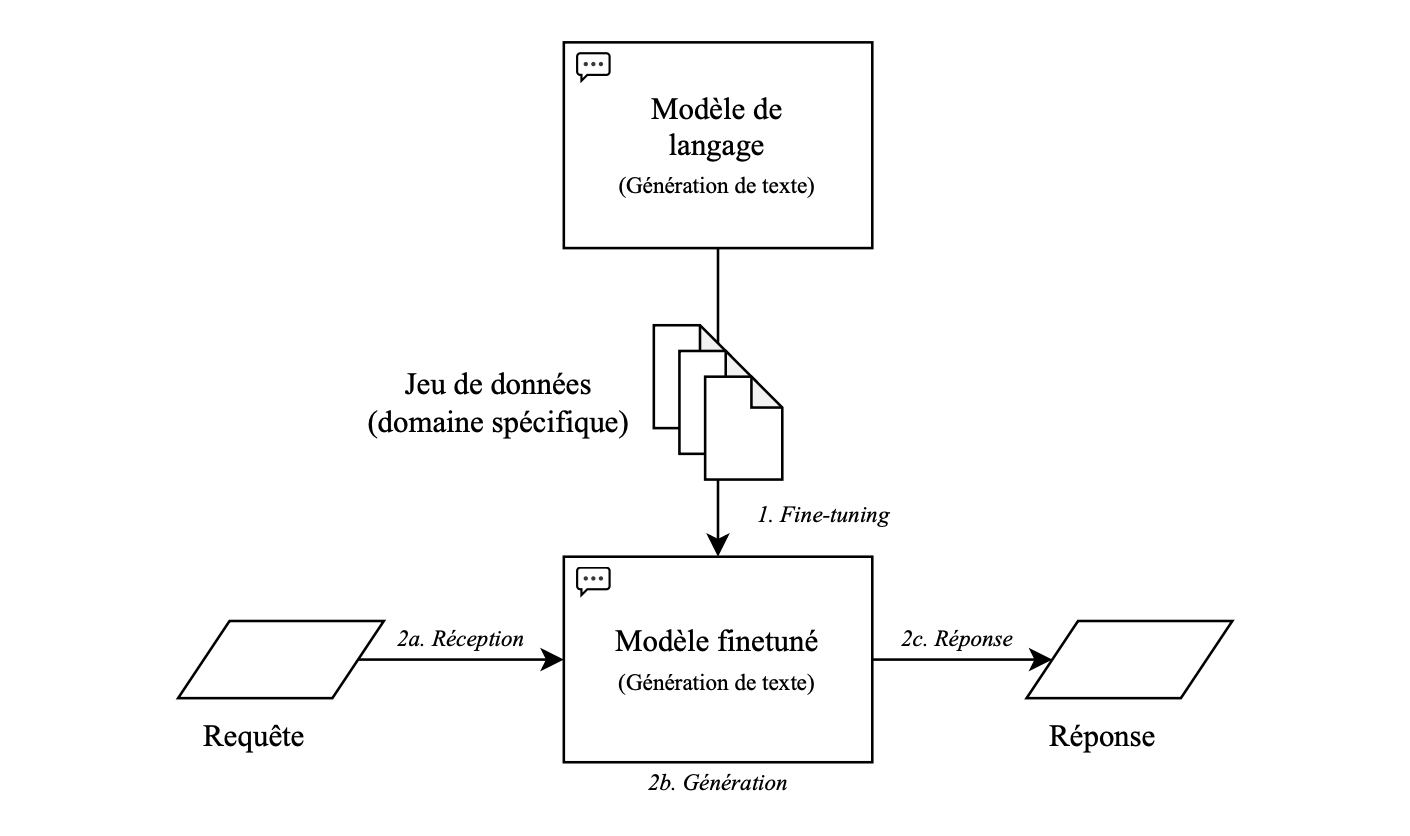
Le fine-tuning est une technique d'apprentissage automatique qui consiste à ajuster un modèle de langage pré-entraîné, par réentrainement sur des données spécifiques à une tâche donnée. Plutôt que de créer un modèle à partir de zéro, le fine-tuning utilise un modèle existant, tel qu'un Grand Modèle de Langage (LLM) comme GPT4 Turbo ou un modèle open source type Mistral 7B, et le spécialise pour répondre à des besoins particuliers. Le fine-tuning peut améliorer la précision des réponses générées par le modèle, mais il peut être limité par la qualité et la représentativité des données d'entraînement.
Fonctionnement du fine-tuning
Le processus de fine-tuning implique plusieurs étapes. Tout d'abord, on commence par sélectionner un modèle de langage pré-entraîné qui servira de base. Ensuite, on alimente ce modèle avec des données spécifiques à la tâche que le chatbot doit accomplir, comme des exemples de questions et de réponses. Ces données sont souvent annotées pour indiquer au modèle ce qui constitue une réponse correcte dans différents contextes.
Une fois que le modèle a été entraîné sur ces données spécifiques, il est prêt à être utilisé pour générer des réponses en fonction des requêtes des utilisateurs. Au fil du temps, le modèle peut être réajusté et ré-entraîné pour améliorer sa performance en fonction des retours des utilisateurs et des nouvelles données disponibles.
Avantages et limitations du fine-tuning
Le principal avantage du fine-tuning est qu'il permet d'améliorer la pertinence et la précision des réponses générées par le chatbot en lui faisant “ingérer” de nouvelles connaissances. En ajustant un modèle pré-entraîné sur des données spécifiques à une tâche, le chatbot devient capable de répondre de manière plus précise aux requêtes des utilisateurs, même dans des contextes complexes ou ambigus.
De plus, le fine-tuning offre une plus grande flexibilité et évolutivité par rapport à la création de modèles à partir de zéro. Plutôt que de devoir entraîner un modèle complet sur des données exhaustives, les développeurs peuvent utiliser des modèles pré-entraînés comme point de départ, ce qui permet de gagner du temps et des ressources tout en obtenant des résultats de haute qualité. En somme, le fine-tuning est une méthode efficace pour améliorer la pertinence des chatbots et offre une approche pragmatique et relativement simple pour améliorer la pertinence des réponses des chatbots.
En revanche, cette approche présente plusieurs limitations. Tout d'abord, le fine-tuning est souvent limité par la qualité, la quantité, et la représentativité des données d'entraînement. De plus, il peut être inefficace pour des tâches complexes ou face à des questions hors de son domaine de spécialisation. Le modèle peut donc générer des réponses inexactes, révélant une limitation dans sa capacité à s'adapter à des requêtes imprévues. Enfin, le fine-tuning est une approche coûteuse en termes financier et environnemental, surtout si le volume de données à traiter est important. C'est là qu'intervient la méthode RAG, une approche essentielle dans le domaine de l'IA générative qui intègre des mécanismes de recherche de documents et de sélection pour fournir des réponses plus précises et fiables.
La méthode RAG : une approche révolutionnaire de l'IA générative
Comprendre la méthode RAG
La RAG (Retrieval Augmented Generation, ou Génération Augmentée de Récupération) est une méthode d’enrichissement qui vise à améliorer la pertinence des réponses fournies par les chatbots en combinant les meilleures pratiques de récupération et de génération de texte. Cette méthode permet au modèle de produire des réponses enrichies par des données actualisées ou spécifiques trouvées dans une base de données externe.
Fonctionnement de la méthode RAG
La première étape de la méthode RAG est la récupération. Ici, le chatbot recherche dans une vaste base de connaissances des informations pertinentes par rapport à la requête de l'utilisateur. Cette recherche est généralement effectuée en utilisant des techniques de recherche d'informations comme la recherche d'entités, la recherche sémantique, ou même des algorithmes de recherche d'information avancés.
Une fois que les informations pertinentes sont récupérées, il convient d’identifier les parties les plus importantes ou les plus pertinentes des informations récupérées, en se concentrant sur les aspects de la requête de l'utilisateur qui nécessitent une réponse spécifique. Cette étape permet au chatbot de se focaliser sur les éléments clés, améliorant ainsi la qualité et la pertinence de la réponse générée.
Enfin, vient l'étape de génération. À ce stade, le chatbot utilise les informations récupérées et les parties mises en avant pour générer une réponse appropriée à la requête de l'utilisateur. Cette génération de texte peut se faire en utilisant des LLM qui sont capables de produire des réponses cohérentes et naturelles.

Les avantages de la méthode RAG pour les chatbots d’IA générative
La méthode RAG offre plusieurs avantages significatifs dans la création de chatbots plus intelligents. Tout d'abord, elle permet de produire des réponses plus pertinentes et spécialisées, ce qui améliore l'expérience utilisateur et renforce la confiance dans le chatbot.
De plus, elle permet une plus grande flexibilité dans la gestion des réponses générées. En ajustant les paramètres de récupération il est possible d’adapter le comportement du chatbot en fonction des besoins spécifiques de leur application, ce qui contribue à une personnalisation accrue et à une meilleure adaptation aux différents scénarios d'utilisation.
Enfin, l’intégration de nouvelles connaissances en continu favorise l'apprentissage du chatbot sans nécessiter de ré-entrainement des modèles. En analysant les interactions avec les utilisateurs et en réajustant constamment les algorithmes de récupération, le chatbot peut s'améliorer au fil du temps, offrant ainsi des réponses de plus en plus pertinentes et précises.
Fine-Tuning versus RAG : l’étude comparative de Wikit
Afin de permettre à ses clients de créer des chatbots les plus pertinents et performants possible, l’équipe R&D de Wikit et le laboratoire Hubert Curien (CNRS) ont réalisé une étude comparative des techniques de fine-tuning et de la RAG pour injecter de la connaissance dans les LLM en utilisant le modèle open source Mistral 7B.
Pour évaluer les réponses générées avec l’une ou l’autre technique, l’équipe R&D s’est appuyée sur deux métriques pouvant s’appliquer aussi bien au fine-tuning qu’à la RAG, et qui rendent compte de la qualité de réponse des LLM dans le cas d’application à des agents conversationnels. La première métrique qui a été mesurée fût la pertinence, pour mesurer à quel point la réponse générée par le LLM était pertinente au vu de la question posée. La seconde métrique qui a été mensurée fût la fidélité, qui représente la véracité factuelle de la réponse générée par le LLM. Cette mesure peut facilement être liée à la détection d’hallucinations.
Les résultats de cette étude comparative ont mis en lumière la supériorité de la technique de la RAG face au fine-tuning. En effet, quel que soit le jeu de données, la RAG a obtenu les meilleurs résultats en termes de pertinence comme de fidélité.
En conclusion, bien que le fine-tuning soit une méthode efficace dans certains cas, la RAG se démarque comme la meilleure option pour améliorer la pertinence des réponses générées par les chatbots d'IA générative. Elle offre une approche plus flexible et évolutive, permettant aux chatbots de s'adapter à une grande variété de contextes et de requêtes. Cette méthode offre une adaptation dynamique aux requêtes des utilisateurs en puisant dans une vaste étendue d'informations disponibles en temps réel, permettant aux chatbots de produire des réponses contextuelles, précises et fiables. En utilisant la technique de la RAG dans la création des chatbots d’IA générative, on assure une meilleure expérience utilisateur et des interactions plus fluides.